Technical Description of L-Store Architecture
Plugin Architecture
L-Store is designed from the ground up to be extensible with support for dynamically loaded plugins. The plugin framework provides a grab bag context that applications can fill with whatever is needed. This could be simple variables, complex data structures, or dynamically loaded functions. This grab bag is then passed as an argument for most object creation routines along with a handle to the configuration file and section or stanza to use for instantiation. The configuration files uses a variation of the standard INI file format with additional support for nested inclusion of files and repeated identically named sections.
The type of service instantiated is completely controlled by the configuration file. To better understand how this is accomplished let us walk through a simple example. A version of the configuration file stripped down to just the essential fragments for illustration purposes is shown below.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | [lio]
timeout = 60
max_attr_size = 1Mi
ds = ibp
rs = rs_remote_client
tpc_cpu = 4
tpc_unlimited = 10000
os = osfile
cache = cache-amp
user=tacketar
[rs_simple_client]
type=simple
fname=/etc/lio/rid.cfg
dynamic_mapping=1
check_interval=60
[rs_remote_client]
type=remote_client
rs_local = rs_simple_client
child_fname = rid-client.cfg
remote_address = tcp://127.0.0.1:6713
dynamic_mapping = 1
check_interval = 3600
check_timeout = 60
|
By default all L-Store routines load the lio section or stanza but this is easily overridden. It is mainly a collection defining which stanzas of the various services to load. We are going to focus on the sequence for instantiating the Resource Service which is controlled via the rs key above. In this case it has the value rs_remote_client. So we are supposed to load the rs_remote_client but in order to do that we need to determine the plugin to use. This is done by looking at the type key in rs_remote_client. In this case we need to instantiate a RS of type remote_client. We look in the global grab bad and see if we find a match. If so, we call the creation function and return it.
It does not end there, though. We can continue down the rabbit hole since a RS of type remote_client also takes as one of its configuration options a RS service it uses locally. The remote service is just for getting a list of resources. It’s not used to do the actual allocations. Just for resource discovery. The local resource service to use is stored in the rs_local key which points to the rs_simple_client stanza. The process now repeats itself. We look at the type key and see that rs_simple_client is to use the simple grab bag object for instantiation.
There are two ways objects and services are installed. For the common services they are automatically included in the binary and nothing special has to be done. The other option is to dynamically load the plugins at runtime. This is accomplished through one or more plugin stanzas similar to the ones in the example below. Each plugin has four required variables. The first two control how they are placed into the grab bag. They define the stanza or section, section key, and the key or name, name key. This is similar to the way they would be accessed or written in the INI file format, section and key.
1 2 3 4 5 | [plugin]
section=segment_load
name=file
library=/etc/lio/plugins/segment_file.so
symbol=segment_file_load
|
Object Service (OS)
This is the workhorse layer for providing traditional file system semantics. The OS handles the creation and removal of objects. An object is just a file or directory. Symbolic and hard links are supported as well. Each object can have an arbitrary collection of metadata or attributes attached, both virtual and traditional. Symbolic linking of attributes between objects is also supported. Read and Write object locking is supported through the os.lock virtual attribute.
Attributes
A traditional attribute is a key/value pair where the key and value are simply stored or retrieved. A virtual attribute is an alias for a piece of C computer code. This code is executed for all read/write operations associated with the attribute name. Virtual attributes would be considered micro-services using iRODS terminology. They are not designed to perform complex tasks. That is what the Messaging Queue Framework is for. Instead virtual attributes are designed to be quick, light weight plugins to perform simple tasks.
There are two types of virtual attributes fixed name and prefix matched. The type of virtual attribute is specified when it is plugged-in. A fixed name attribute is the simplest. It provides a direct mapping between attribute name and plugin. The attribute os.link is a fixed virtual attribute. Querying this attribute returns the object type, for example file, directory, or link. A prefix matched attribute means the virtual attribute name is a prefix of the attribute name requested by the user. For example os.timestamp is a prefix virtual attribute and would be triggered by a request to access the attribute os.timestamp.my.date. In fact it gets triggered anytime the first 12 characters of the attribute requested correspond to os.timestamp. It is easiest to understand the differences by looking at some examples.
The sequence to resolve an attribute is as follows: The OS first scans the list of fixed name virtual attributes for a match. If none occur, then it scans the prefix matched virtual attributes looking for a match. If still no match a lookup is performed for a traditional attribute with that name.
Attributes use a dot separated namespace. The native attributes supported by the OS all begin with os and are listed below:
Fixed virtual attributes:
- os.lock – Retrieve an object’s read/write locks
- os.link – Retrieve an object’s symbolic link
- os.link_count – Returns how many times the object referenced
- os.type – Returns the object type (file, directory, symbolic link, etc)
- os.create – Returns the object creation time
Prefix matching virtual attributes:
- os.attr_link – Returns an attributes symbolic link
- os.attr_type – Returns the type of attribute (virtual, symbolic, text, etc)
- os.timestamp –Sets or retrieves a timestamp attribute
The example below shows the output of the os.link fixed virtual attribute. In the example, /lio/lfs is the L-Store mount point and we have created a symbolic link of bar->foo which shows up when probing the os.link attribute. Note that foo returns (null) as expected because it is not a symbolic link.
1 2 3 4 5 6 7 8 9 10 11 12 | bob@depot1:/lio/lfs/testing# echo "bar" > foo
bob@depot1:/lio/lfs/testing# ln -s foo bar
bob@depot1:/lio/lfs/testing# ls -l
total 0
lrwxrwxrwx 1 root root 3 Mar 21 15:43 bar -> foo
-r--r--r-- 1 root root 4 Mar 21 15:43 foo
root@depot1:/lio/lfs/testing# lio_getattr -al os.link foo bar
object=/testing/foo
os.link=(null)
object=/testing/bar
os.link=foo
|
In the nextexample, we explore working with virtual attributes. Now let us create a timestamp just for my use. Let us call it my.date and I would like to add a little text to it to let me know who created it which was me. I could just store my system date in the attribute my.date along with the me but in a distributed environment it is probably better to use a synchronized clock that we can all agree on. In this case, we will use the clock in the OS. To do that, we will need to use the os.timestamp virtual attribute. Since this is a prefix matched virtual attribute it gets triggered anytime the virtual attribute is a prefix of the attribute being specified. In this case, that is os.timestamp. os.timestamp takes the rest of the attribute name passed and creates a normal traditional attribute using that name. The epoch time, in seconds, is stored in the traditional attribute along with provided text, separated by the pipe, |, symbol. For the example we want that to be my.date. This means we need to form the composite attribute os.timestamp.my.date and use that when setting the attribute.
1 2 3 4 | bob@depot1:/lio/lfs/testing# lio_setattr -as os.timestamp.my.date='me' foo
bob@depot1:/lio/lfs/testing# lio_getattr -al my.date foo
object=/testing/foo
my.date=1363899327|me
|
Notice that the lio_setattr command created the my.date indirectly. The os.timestamp virtual attribute appended our extra text to the timestamp.
OS Implementations
Currently the workhorse OS implementation is os_file. This uses a traditional disk file system to store all metadata. As a result this implementation does not work between nodes. In order to overcome this limitation we have added the os_remote_client and os_remote_server implementations. These allow the OS from a client to connect to a remote OS acting as a server. The OS remote server will then use the os_file driver for the actual backing store. This combining of existing building blocks to provide new functionality is a real strength of L-Store and is done routinely.
The current os_file driver has inherent limitations since it is isolated to a single machine and uses a traditional file system to store data. One can get pretty good scalability using an SSD for the disk. Likewise using the linux rsync and inotify tools one can achieve high availability if the primary OS server dies. We do this for the current version of L-Store and plan on adding it to the new version as well. In order to scale to billions of files one needs another approach. We have been looking at various NoSQL databases and plan on using one of them as the core for a new NoSQL OS. Currently the most promising is Apache Cassandra.
Authentication and Authorization (AuthN and AuthZ)
The primary authentication system in development is relatively traditional using a username for identification and a password, key, or certificate as credentials to vet identity. Also in the works is a utility that will work in conjunction with this authentication module that can be used to create an authentication session. This tool would securely cache the user’s identity and credentials for a limited duration and environmental scope (for example: 1 hour and only within a particular login session on the user’s computer). This tool will give the user the convenience of being able to perform operations on the L-Store system without having to resupply authentication credentials with every operation. This tool fulfills the same role in L-Store that ssh-agent does in the SSH suite.
Alternate authentication systems will also be supported and a great deal of work is being done to carefully design an authentication framework that can support modules for all future authentication and user management models. Authentication and identity management is greatly more complicated in a distributed system, such as L-Store, than in a local one. Such a system must properly enforce security policy while operating across administrative domains and also have the flexibility to allow integration with a variety of external authentication/user management systems. Additionally distributed systems must be capable of working within untrusted environments, with untrusted clients, and over untrusted networks.
A user’s identity in a remote/distributed file system, unlike in a local file system, is not the same as the user’s operating system account on the local computer. A user thus has both a local identity and a remote file system identity. Generally that remote identity would be claimed and vetted for use with more than a single operation so that identity must be retained but with appropriately restricted access. In many cases, a one-to-one mapping of remote identity to local identity is sufficient, however being able to restrict the remote identity credentials to a single application process or session is needed in some use cases. Additionally a local user on the client machine may need to take on multiple remote identities, or it may be desirable to allow multiple users on the client machine to share a single remote identity, either fully or in a limited or delegated fashion. To add to the complexity there may be other user identity systems to integrate with, for example a LDAP single sign-on service. Integration could take the form of either mapping the external service’s identities to identities used by the distributed file system or using the service as the file system’s own user identity authority. In designing the authentication framework for L-Store, we take the view that supporting all of the above scenarios should be possible.
Collaborating with the CMS project and operating as an OSG (Open Science Grid) site has given the ACCRE team direct experience with some complex security and user management scenarios. CMS researchers juggle many identities and operate between many administrative domains when doing work interactively, when managing batches of long-running jobs, and when storing and accessing datasets. A X.509 certificate based system provides an identity that can be used across grid computing sites for Grid services but beyond that the sites are heterogeneous. Researchers often have separate accounts on clusters at a handful of sites. These accounts must get mapped to a Grid account to access Grid services and in some cases when Grid services are accessed at remote sites these grid identities themselves get mapped onto site specific accounts. Grid credentials are capable of being delegated through creating proxy certificates and this is used for creating sessions through time-limited credentials, delegating access to batches of computational jobs that may run at a variety of sites as a variety of users, and arranging third party transfers of data. At the Vanderbilt site, the L-Store system has to manage access to the CMS datasets for local and remote Grid users. In short it is vital to have a flexible and robust authentication framework so L-Store can integrate into complex systems.
The authorization module in development is non-traditional in design and implementation. The module is designed to be enormously flexible and powerful to enable the use of rich and unique authorization policies. However the ability of the module to behave just like familiar authorization systems to the user is also priority. The module is designed to provide a superset of the capabilities of common, traditional authorization systems and is designed to be easily configured to replicate traditional behavior. This authorization module uses an embedded Prolog logic engine to process authorization rules and make authorization decisions.
The authorization hooks in the object service make authorization requests using a tuple composed of the action proposed, the object subject to the action, and the credentials presented, where object is a generalization that encompasses files and attributes, and the credentials are vetted by the authentication module. Based on the request tuple, the authorization rules, and any relevant metadata (associated with the object such as a file’s owner and permissions attributes and the attributes of a containing folder, or associated with the credentials such as an attribute containing a user’s group membership) the module will either allow or deny the action proposed.
The authorization rules are not hard coded into the module but rather they are configurable both system wide and on a domain/folder basis and can be reconfigured on a running system. Rule sets are being created to model standard POSIX (Unix/Linux) style permissions and NFSv4 ACLs (an open standard nearly the same as the ACL systems used by OSX and Windows operating systems). Authorization rules can potentially be used to create whole custom authorization systems (for example a role based access control system) or extend the common authorization systems (for example adding the capability for a file owner to share a file with a colleague by emailing them a hyperlink containing a key for anonymous, read-only, and perhaps time-limited access).
Large binary objects are physically stored outside of the Object Service on Depots but the data is only accessible via handles to the data in the exNode. These handles to the data provide limited capabilities to read or modify the data. Thus authorization policy is enforced by returning different views of the exNode with different capability handles based on the action approved by the authorization system. For example if just read-only access is approved by the authorization system then only a version/view of the exNode containing solely read-only handles to the physical data will accessible.
Resource Service (RS)
The RS has two functions: Maintain a list of available resources and map user requests to physical resources. A resource or RID has three mandatory attributes (rid_key, ds_key, and host) and an arbitrary collection of user defined attributes. The rid_key is unique, so dynamic mapping can be enabled to automatically remap resources. For example changing the hostname or moving the resource to another depot. The data service key, ds_key, is the value passed to the data service in order to reserve the space. Technically host is not mandatory but the most common failure group is host based. It is best to stripe data across depots if possible. Another common attribute is site or lun to allow for replication or data movement between remote sites. It’s easiest to understand the difference by looking at an actual RID definition as shown in the example below.
1 2 3 4 5 | [rid]
rid_key=1301
ds_key=illinois-depot1.reddnet.org:6714/1301
host=illinois-depot1.reddnet.org
lun=ncsa
|
In this case the rid_key is just the RID id, 1301. The RID is located in the depot with the host name illinois-depot1.reddnet.org. The ds_key is an amalgam of this information along with the IBP server port, 6714, and is passed directly to the DS. The DS then parses the information and uses it to locate the resource. There is an additional attribute named lun with the value ncsa. This is used to signify that the depot is located at NCSA. Additional attributes can be added as needed.
A resource query is used to find viable locations to place data. The resource query itself is a text string representing a postfix boolean expression. The available operators are AND, OR, NOT, KV_EXACT_MATCH, KV_PREFIX_MATCH, and KV_ANY. The names are pretty self explanatory (KV =Key/Value). There are a couple of modifiers that can be applied to the KV operators: KV_UNIQUE, and KV_PICKONE. The purpose of KV_UNIQUE is straightforward; make sure the KV selected is unique. KV_PICKONE is normally used in conjunction with the KV_PREFIX_MATCH operator. It is designed to pick and use a single answer for all subsequent requests. For example assume we have a bunch of resources some with lun=vu_accre and others with lun=vu_physics. We want all the data to be stored at either ACCRE or physics but not both. To do this we use the KV_PREFIX_MATCH with the KV_UNIQUE modifier. The resource query is associated with a segment and stored in the exNnode. The segment driver passes query to the RS along with other information, like the number of resources and size, to find suitable matches.
The workhorse RS implementation is rs_simple which is designed to work in a single process space, thus it is not shared between processes. For that, one uses the rs_remote_client and rs_remote_server drivers. This allows all clients to use a common RS. Like the OS versions, the rs_remote_* drivers use the rs_simple underneath to do the heavy lifting. rs_simple supports dynamic reloading of the configuration file. One simply needs to touch the configuration file to trigger reloading the configuration. If dynamic mapping is enabled any resource host changes are automatically picked up on the next read or write operation. The rs_remote_server automatically detects the change in its underlying RS and propagates it to all the rs_remote_clients registered with it. The RS service tracks space usage and if the host is up, it adjusts resources based on this information.
Data Service
All actual disk I/O is handled in this service. Currently ds_ibp is the only implementation and uses IBP as the underlying storage mechanism. This IBP implementation will be the focus of this section. IBP provides a best-effort storage service with stronger guarantees being enforced by higher levels of the software stack. In the L-Store case that is the segment service’s responsibility.
As noted, IBP implements a primitive storage service that is the foundation of LN. As the lowest layer of the storage stack that is globally accessible from the network, its purpose is to provide a generic abstraction of storage services at the local level, on the individual storage node, or depot. Just as IP is a more abstract service based on link-layer datagram delivery, so IBP is a more abstract service based on blocks of data (on disk, memory, tape or other media) that are managed as byte arrays. By masking the details of the local disk storage fixed block size, different failure modes, local addressing schemes this byte array abstraction allows a uniform IBP model to be applied to storage resources generally (e.g. disk, ram, tape). The use of IP networking to access IBP storage resources creates a globally accessible storage service.
As the case of IP shows, however, in order to have a shared storage service that scales globally, the service guarantees that IBP offers must be weakened. To support efficient sharing, IBP enforces predictable time multiplexing of storage resources. Just as the introduction of packet switching into a circuit switched infrastructure dramatically enhanced the efficient sharing of the wires, IBP supports the time-limited allocation of byte arrays in order to introduce more flexible and efficient sharing of disks that are now only space multiplexed. When one of IBP’s leased allocations expires (per known schedule or policy), the storage resource can be reused and all data structures associated with it can be deleted. Forcing time limits puts transience into storage allocation, giving it some of the fluidity of datagram delivery; more importantly, it makes network storage far more sharable, and easier to scale. An IBP allocation can also be refused by a storage resource in response to over-allocation, much as routers can drop packets; and such “admission decisions” can be based on both size and duration. The semantics of IBP storage allocation also assume that an IBP storage resource can be transiently unavailable. Since the user of remote storage resources depends on so many uncontrolled, remote variables, it may be necessary to assume that storage can be permanently lost. Thus, IBP is also a best effort storage service.
To enable stronger storage services to be built from IBP without sacrificing scalability, LN conforms to classic end-to-end engineering principles that guided the development of the Internet. IP implements only weak datagram delivery and leaves stronger services for end-to-end protocols higher up the stack; similarly, IBP implements only a best effort storage service and pushes the implementation of stronger guarantees (e.g. for availability, predictable delay, and accuracy) to end-to-end protocols higher up the network storage stack. In its weak semantics, IBP models the inherent liabilities (e.g. intermittent unreachability of depots, corruption of data delivered) that inevitably infect and undercut most attempts to compose wide area networking and storage. But in return for placing the burden for all stronger services on the end points (i.e. on the sender/writer and receiver/reader), this approach to network storage tolerates a high degree of autonomy and faulty behavior in the operation of the logistical network itself, which leads directly to the kind of global scalability that has been a hallmark of the Internet’s success.
Since IBP allocations are designed to be transient you may be wondering how to get around this limitation. This is accomplished by periodically contacting the depot and extending the allocations duration. We call this process warming the file. If the depot refuses to extend the expiration, then data is migrated to another location.
Another issue commonly encountered in large scale storage is silent bit errors. The most common reference to silent bit errors is for a drive changing a bit’s state that is not detected by the disk drive. Given manufacturer specified unrecoverable bit error rates of 1 in 1014 or 1015 and the size of available drives, these do occur. But a more common silent bit error is from a drive or computer crash resulting in garbage being stored of portions of an allocation. The file system may replay the log and correct some of these errors but it does not catch all of them. This is even harder in a distributed context since the IBP write operation will have completed from the remote applications standpoint but before the operating system had the ability to flush the data to disk. One option would be to only return success to the remote client after a flush to disk had occurred but that would greatly impact performance.
Another option is to interleave block-level checksum information with the data. This has some impact on disk performance but much less than the alternative. The tradeoff is much greater processing power to calculate the checksums. This is done on the depot only which has plenty of excess computing power. Enabling block-level checksums is done at the allocation’s creation time. When an allocation has block-level checksums enabled every read and write operation involves comparison to the existing checksum to verify data integrity. If an error occurs, it immediately notifies the remote application allowing it to properly deal with the issue. This normally triggers either a soft or hard error, typically in the segment_lun driver, which is corrected by another layer. These errors are kept track of and used to update the system.soft_errors and system.hard_errors attributes. These are used, in turn, to trigger more in depth inspections of the object.
Segments
The various segment drivers are responsible for processing user I/O requests and mapping that to physical resources. It can use the DS and RS services in order to do this. The segment drivers support the traditional I/O operations read, write, truncate, remove, and flush but also inspecting the data for integrity, insuring the RS query is properly enforced, and cloning data between segments. There are many different segment drivers implemented and they are commonly combined together, see section 8.6.7, to extend functionality. The segments themselves are all contained within the exNnode with the exNode controlling how the various segments are coupled together and presented to the application.
Interfacing with other repositories
Segment drivers can be used to interface with other repositories. For example iRODS, Amazon S3, WebDAV, to name a few. The simplest example is mapping an L-Store file to a local file. This is done using the segment_file driver discussed in Section B.6.2. But due to the ease of extending L-Store functionality using the provided plugin framework, adding support for other repositories is well defined. Once implemented they can then be combined together with other segment drivers to provide additional functionality, for example combining the segment_cache driver with segment_file to enable local caching of a file.
segment_file
This is the only segment that does not use the DS or pass the DS on to a lower level. It simple maps an object to a physical file on a local disk and is more of a testing driver.
segment_cache
Caching segment driver. The segment_jerase driver does not allow reading and writing of arbitrary offsets and sizes. It can only perform I/O on fixed size blocks. The cache driver handles the impedance mismatch between what the user wants and segment_jerase needs by buffering data. There are two different types of caching implemented. The traditional Least Recently Used (LRU) method and a variation of Adaptive Multi-stream Preteching (AMP; Gill 2007).
segment_jerase
The primary driver providing fault tolerance. The driver implements all the functionality provided by Jim Planks’s Jerasure library (Plank 2008). The most notable being the Reed-Solomon encoding.
segment_log
This driver implements a log-structured file. A log structured file only supports append operations, i.e. data is never overwritten. Instead it is appended to the file along with a new extent defining what was appended. This allows one to replay the log and create different versions of the file at any point in the log. The log segment is comprised of three other segments:
- Base Normal flat address space used as the base for the file to apply the changes
- Log extents This just contains all the extents (offset and length pairs) for changes.
- Log data All the data corresponding to the extents.
The log extents are kept separate from the log data to facilitate quick access over the WAN since the extents can be read in large reads with the log data being accessed as needed. Any range requests not in the log is retrieved from the base.
This driver has additional functionality to add additional logs on top of the current log and also merge existing logs with the base. This driver provides the foundation for handling file versioning, snapshotting, and regional caching.
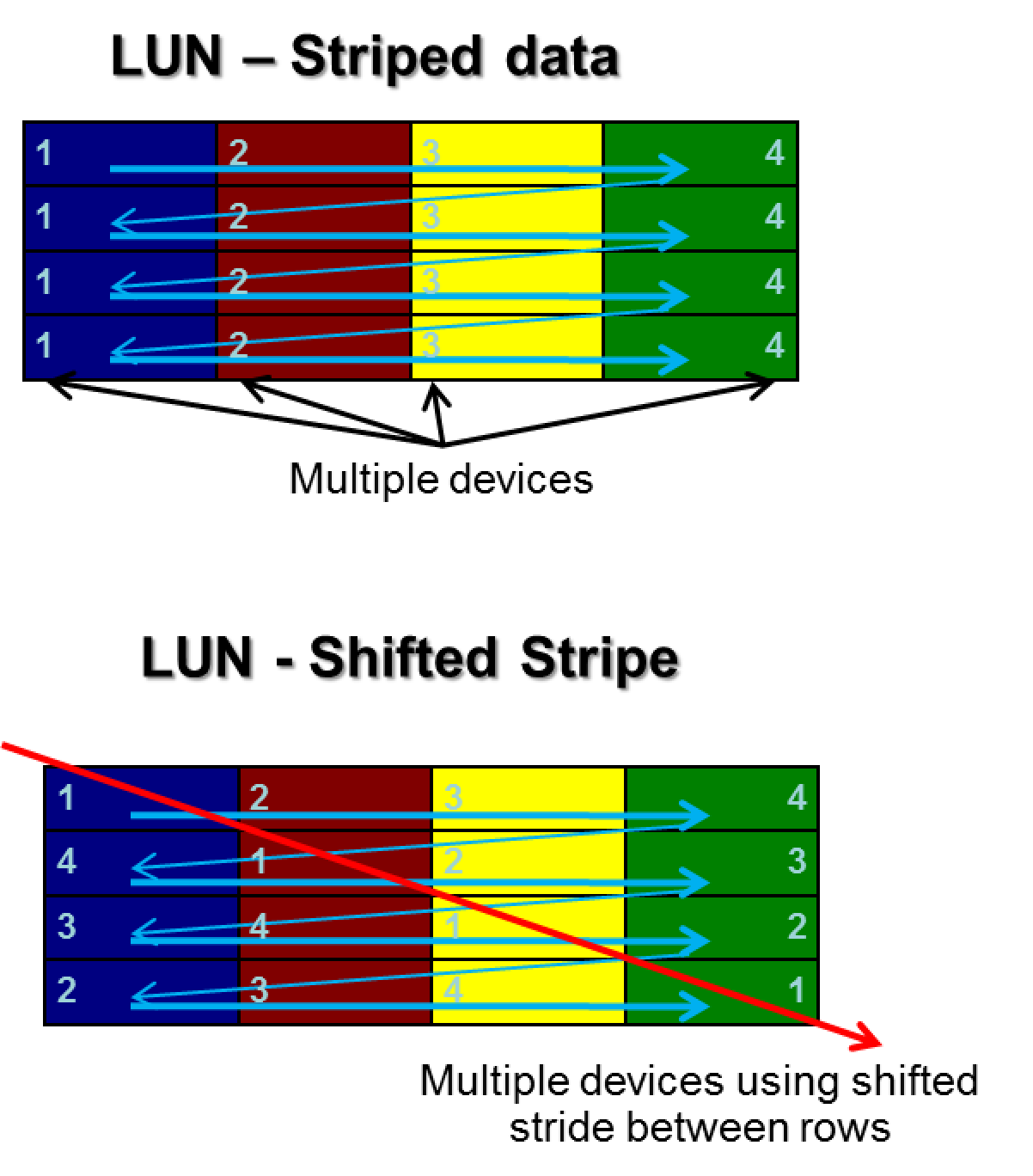
Examples of the segment_lun driver data layout. In each example 4 allocation or devices are used. Each colored square represents a contiguos data chunk. Typically this chunk size is 16kb. The arrows show the logical byte ordering of the data. The data can be shifted (bottom diagram) in order to interleave data and parity on the same device or allocation.
segment_lun
This driver takes a collection of allocation and turns them into a logical unit or LUN. Similar to what a hardware based RAID appliance does. It takes as input the number of virtual disks, chunk size, optional shift, and the RS query to control data placement. It then takes that information and converts it into a flat address space for use. Normally a chunk size of 16k is used.
ExNodes
ExNodes are the segment containers. It is unusual for an exNode to contain a single segment. It is much more likely to contain many segments organized in a hierarchy to provide more complex functionality. The default exNode, using Reed-Solomon 6+3, has 3 segments. The topmost being a cache segment to allow an arbitrary offset and length to be accessed. The cache segment will convert the arbitrary offset and length and map it into a whole set of pages that the Jerase segment can handle. The Jerase segment then breaks up the request into much smaller chunks, typically 16k, and intermingles with it a 4-byte page id which is used to detect out of sync allocations. Each of these chunks are now 16k + 4 bytes in size. This is then passed down to the LUN driver which maps it to individual allocations and issues the actual I/O operation. The lio_signature command can be used to probe the exNode structure. The example below shows the result of executing the lio_signature command on the file foo from the earlier example.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | bob@depot1:/lio/lfs/testing# lio_signature foo
cache()
jerase(
method=cauchy_good
n_data_devs=6
n_parity_devs=3
chunk_size=16384
w=-1
)
lun(
n_devices=9
n_shift=0
chunk_size=16388
)
|
Putting it all together
To illustrate how the different services and layers fit together we will use the file foo created earlier and migrate the data from its initial location on Illinois-depot1.reddnet.org to depots at Vanderbilt, reddnet-depotXX.reddnet.org. Since we have plenty of individual depots there we will add the constraint that all allocations in a stripe reside on unique hosts. The exNode attribute is called system.exnode. In the earlier example, we used the LIO command line tool, lio_getattr, but we could have just as easily used the native Linux getfattr command. This command translates carriage returns into their octal value 012, so the output all fits on a line. For ease of readability, we will use the sed command to translate it back to carriage returns as shown in following example.
1 2 3 4 5 6 7 8 9 10 | bob@depot1:/lio/lfs/testing# getfattr -n system.exnode foo | sed -e 's/\\012/\n/g' | grep read_cap
read_cap=ibp://illinois-depot1.reddnet.org:6714/1303\\#HYZYqP8Kr084ZhCn5R4Xo-qbEBOXTWHw/1193237927050283380/READ
read_cap=ibp://illinois-depot1.reddnet.org:6714/1309\\#zaX4pV7S+Rzfh+CIQF7PWBU0XU3ip5Cl/8142985625835886494/READ
read_cap=ibp://illinois-depot1.reddnet.org:6714/1305\\#FLBccPC2cVdOZvw+SbIIyv5q8ZS2jZm6/1327633227782700733/READ
read_cap=ibp://illinois-depot1.reddnet.org:6714/1301\\#fiskXAQtMOWzO+h8sex13RPrNaSJ-s81/1552463313520192294/READ
read_cap=ibp://illinois-depot1.reddnet.org:6714/1311\\#wDHS5s320cmSff3erlKd1l14U+EN71Jn/4545713708264805990/READ
read_cap=ibp://illinois-depot1.reddnet.org:6714/1310\\#bV0zRWCtoyo901YRQLTszYsECMtu5Jh/11111074597559848935/READ
read_cap=ibp://illinois-depot1.reddnet.org:6714/1307\\#JMXuOjkH-wr0MYu5t2r2Ak7D2yIIiPL8/7595365900388334614/READ
read_cap=ibp://illinois-depot1.reddnet.org:6714/1306\\#GxuHi-XHWTl8vEV16yrIB2Zu1TttJU2z/5873569038756943851/READ
read_cap=ibp://illinois-depot1.reddnet.org:6714/1308\\#bUqNFlXFu5qvV2NIO8IIsRE9NLNE9l6u/14679269252788024022/READ
|
We are just pulling out the IBP Read capabilities, which describe where the data blocks are located and how to access them. As you can see in the above output, all the data is sitting where we think it is on illinois-depot1.reddnet.org. Now let us change the RS query to use unique VU depots. The RS query is contained in the query_default tag for the LUN segment stanza located in the exNode. For that we have written a couple of simple scripts, change_location.sh and query_change.sh shown in examples below:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | ----Script: change_location.sh----
#!/bin/bash
if [ "${1}" == "" ]; then
echo "${0} [ncsa1|ncsa2|vandy] file"
exit
fi;
case "${1}" in
"ncsa1")
qnew="simple:1:rid_key:1:any:67;1:host:1:illinois-depot1.reddnet.org:1;3:any:1:any:1"
;;
"ncsa2")
qnew="simple:1:rid_key:1:any:67;1:host:1:illinois-depot2.reddnet.org:1;3:any:1:any:1"
;;
"vandy")
qnew="simple:1:host:1:any:67;1:lun:1:vandy:1;3:any:1:any:1"
;;
*)
echo "Invalid destination"
exit;
;;
esac
query_change.sh ${2} ${qnew}
|
1 2 3 4 5 6 7 8 9 10 11 12 | ----Script: change_location.sh----
#!/bin/bash
if [ "${1}" == "" ]; then
echo "${0} file new_query"
exit
fi;
lio_getattr -al system.exnode ${1} | sed -e "s/query_default=.*/query_default=${2}/g" > /tmp/query.$$
lio_setattr -af system.exnode=/tmp/query.$$ -p ${1}
rm /tmp/query.$$
|
change_location.sh has three predefined RS query strings:
- nsca1 – Locate data on unique RIDS using only Illinois-reddnet1.reddnet.org.
- ncsa2 – Locate data on unique RIDS using only Illinois-reddnet2.reddnet.org
- vandy – Locate data on unique RIDS and unique hosts using the vandy LUN which is comprised of depots with hostnames reddnet-depotN.reddnet.org.
Based on the user option it selects one of the sites and then calls query_change.sh to make the change. Query_change.sh use the lio_getattr/lio_setattr commands along with sed to make the change. At this point you may be wondering, How did *foo initially get stored on Illinois-depot1?* This is controlled by the parent directory’s exNode. Any objects created inside the directory, directly inherit the parent exNode. If you look in the LFS mount you will see three directories: nsca1, ncsa2, and vandy. Each of these directories has a different RS query controlling the data placement. Since foo was created in nsca1 it inherited the ncsa1 RS query string and placed the data there.
The effect of change_location.sh can be seen below:
1 2 3 4 5 | bob@depot1:/lio/lfs/ncsa1/testing# lio_getattr -al system.exnode foo | grep query_default
query_default=simple:1:rid_key:1:any:67;1:host:1:illinois-depot1.reddnet.org:1;3:any:1:any:1
bob@depot1:/lio/lfs/ncsa1/testing# change_location.sh vandy foo
bob@depot1:/lio/lfs/ncsa1/testing# lio_getattr -al system.exnode foo | grep query_default
query_default=simple:1:host:1:any:67;1:lun:1:vandy:1;3:any:1:any:1
|
The first command above just pulls out the attribute default_query tag and displays it. We then execute the change_location.sh script, and another run another query to shows that the segment locations have changed as shown in the highlighted lines. The format of the query is not important for the example and will be discussed briefly. The query is comprised of a collection of , separated tuples. The tuples are individual operations broken into the following : separated format:
OP:key:KEY_OP:val:VAL_OP
The OP, KEY_OP, and VAL_OP are integers representing the various operations mentioned earlier. The key and val are text string arguments that KEY_OP and VAL_OP use. For some operations these values are not used. In that case , any is normally used to signify this.
Now let us check things using lio_inspect:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | bob@depot1:/lio/lfs/ncsa1/testing# lio_inspect -i 20 -o inspect_quick_check foo
2605765806391400866: Inspecting file /testing/foo
2605765806391400866: Cache segment maps to child 7897007012983383082
7897007012983383082: jerase segment maps to child 7731792479974313281
7897007012983383082: segment information: method=cauchy_good data_devs=6 parity_devs=3 chunk_size=16384 used_size=147492 mode=1
7897007012983383082: Inspecting child segment...
7731792479974313281: segment information: n_devices=9 n_shift=0 chunk_size=16388 used_size=147492 total_size=147492 mode=1
7731792479974313281: Checking row (0, 147491, 147492)
7731792479974313281: slun_row_size_check: 0 0 0 0 0 0 0 0 0
7731792479974313281: slun_row_placement_check: -102 -102 -102 -102 -102 -102 -102 -102 -102
7731792479974313281: status: FAILURE (0 max dev/row lost, 0 lost, 0 repaired, 9 need moving, 0 moved)
7897007012983383082: status: FAILURE (0 devices, 0 stripes)
ERROR Failed with file /testing/foo. status=20 error_code=0
--------------------------------------------------------------------
Submitted: 1 Success: 0 Fail: 1
ERROR Some files failed inspection!
|
Above we used the lio_inspect command to show more details about the file. The option, -o inspect_quick_check, is used to check for errors, and we also enabled more detailed information, -i 20. The numbers on the left correspond to the segment ID of which there are 3. The last number refers to the resource allocation. Notice the slew of -102 errors on the slun_row_placement_check. That means the data is good but it is in the wrong location, which is what the change_location.sh script did. Effectively, we told the segment that it should be located on a Vanderbilt depots, but the actual data is still stored on the illinois-depot1 depot. Correcting this mismatch is easy, and allows us to do basic data management as shown:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | bob@depot1:/lio/lfs/ncsa1/testing# lio_inspect -i 20 -o inspect_quick_repair foo
2605765806391400866: Inspecting file /testing/foo
2605765806391400866: Cache segment maps to child 7897007012983383082
7897007012983383082: jerase segment maps to child 7731792479974313281
7897007012983383082: segment information: method=cauchy_good data_devs=6 parity_devs=3 chunk_size=16384 used_size=147492 mode=4
7897007012983383082: Inspecting child segment...
7731792479974313281: segment information: n_devices=9 n_shift=0 chunk_size=16388 used_size=147492 total_size=147492 mode=4
7731792479974313281: Checking row (0, 147491, 147492)
7731792479974313281: slun_row_size_check: 0 0 0 0 0 0 0 0 0
7731792479974313281: slun_row_placement_check: -102 -102 -102 -102 -102 -102 -102 -102 -102
7731792479974313281: slun_row_placement_fix: 0 0 0 0 0 0 0 0 0
7731792479974313281: status: SUCCESS (0 max dev/row lost, 0 lost, 0 repaired, 9 need moving, 9 moved)
7897007012983383082: status: SUCCESS (0 devices, 0 stripes)
Success with file /testing/foo!
--------------------------------------------------------------------
Submitted: 1 Success: 1 Fail: 0
bob@depot1:/lio/lfs/ncsa1/testing# lio_getattr -al system.exnode foo | grep read_cap
read_cap=ibp://reddnet-depot9.reddnet.org:6714/3301\#PohVY7F1aD9rdou3m5Q71iSPscLJyPQ5/5103495629362325813/READ
read_cap=ibp://reddnet-depot1.reddnet.org:6714/3005\#xcoQuoPynFs0Frwc47MzISFo6+YPIGUQ/11519844186520566116/READ
read_cap=ibp://reddnet-depot3.reddnet.org:6714/3085\#lDJnQZUta2Sm3AI2QOtsk2VqF0ssRbSs/7281358841736548979/READ
read_cap=ibp://reddnet-depot8.reddnet.org:6714/3278\#4kSH5AVFbLeDgVsufH9NhG2eQCOTHIe4/12830054284326113551/READ
read_cap=ibp://reddnet-depot5.reddnet.org:6714/3150\#2vlq6369cK-iLFxDdtI4s6ZGJN59BrHw/10565121898315427550/READ
read_cap=ibp://reddnet-depot4.reddnet.org:6714/3124\#ZzBqKNeA0KgP0lrQmcWLZJm20lEQtZeT/2408774212259981079/READ
read_cap=ibp://reddnet-depot6.reddnet.org:6714/3187\#gh4ytNLnKGF+y75DSCz-DaZN-xbAuHtg/14267407348897555811/READ
read_cap=ibp://reddnet-depot7.reddnet.org:6714/3222\#dEbDyQ2xEBH2PRsDuisTgIqdIdxrmiWI/2302119019249640684/READ
read_cap=ibp://reddnet-depot2.reddnet.org:6714/3068\#7duw3cTjx-GyIwogs4FWIB91Pk8zGwBG/15574321931192607090/READ
|
In the above lio_inspe3ct call we changed the inspection option from quick-check to quick_repair. This causes the lio_inspect tool to move the actual data from illinois-depot1 to several Vanderbilt depots (reddnet-depots 1-9). This time you see the same -102 error on the placement check but on the next line you see the data migration was successful which is signified by the 0’s for all the allocations in the stripe. Just to be safe we do a check of the eXnode by looking at the read capabilities again using lio_getattr just like we did in the previous example. The data blocks have been moved to the Vanderbilt LUN and each allocation is on a different depot.
Message Queue Framework (MQ)
How individual compute nodes connect and find one another greatly impacts not just the software design but also controls the scalability. Message queues were designed to provide an asynchronous communication method allowing the sender and receiver to check the queue at different times. By making the communication asynchronous it opens the door for much greater application and task concurrency. Common communication patterns also start to arise which can be templated and standardized making development much easier. The simplest pattern is a direct peer-to-peer communication. But one can make much more sophisticated patterns publish-subscribe to track types of events. Overlay networks can be created to route around network problems or move high priority traffic to a dedicated network.
RabbitMQ is being used for the previous generation of L-Store to perform consistency checks, warm allocations, calculate checksums, and perform drive repairs. One of the big drawbacks of RabbitMQ is its Java centric support. When writing the current version of L-Store we evaluated many of the MQ libraries available. We wanted an MQ toolkit that was lightweight, language agnostic, had a broad user base, and easy to use. Ultimately we decided on using ZeroMQ. ZeroMQ has its own idiosyncrasies, but they could be worked around. In keeping with the rest of the L-Store design, instead of directly using ZeroMQ we instead made an abstract MQ interface that the rest of L-Store uses. Behind the scenes ZeroMQ is used but the abstraction means we can replace it in the future and without having to change the whole code base. During the evaluation process we tested many patterns in ZeroMQ heartbeating, overlay routing, publish/subscribe, and several more. This exposed many of the idiosyncrasies mentioned earlier, and we came up with work-arounds to mesh ZeroMQ into the generic task operator (GOP) framework that underpins the whole concurrency model in L-Store. This is similar to an RPC call but with task queues allowing you to consume tasks as they complete, or all at once in the end, or only process failed tasks. Nested Queues are also supported. All tasks run through the GOP framework thread tasks, MQ tasks, and IBP operations. This makes coding things much easier since you do not have to marshal up a connection to a host or spawn a thread. You just call the particular GOP task constructor and execute it. The current version does not have all the functionality yet, namely interior MQ nodes for routing and brokers are only prototyped. Adding them is straightforward and will be done in the near future when we decentralize the Warmer and Inspection operations.
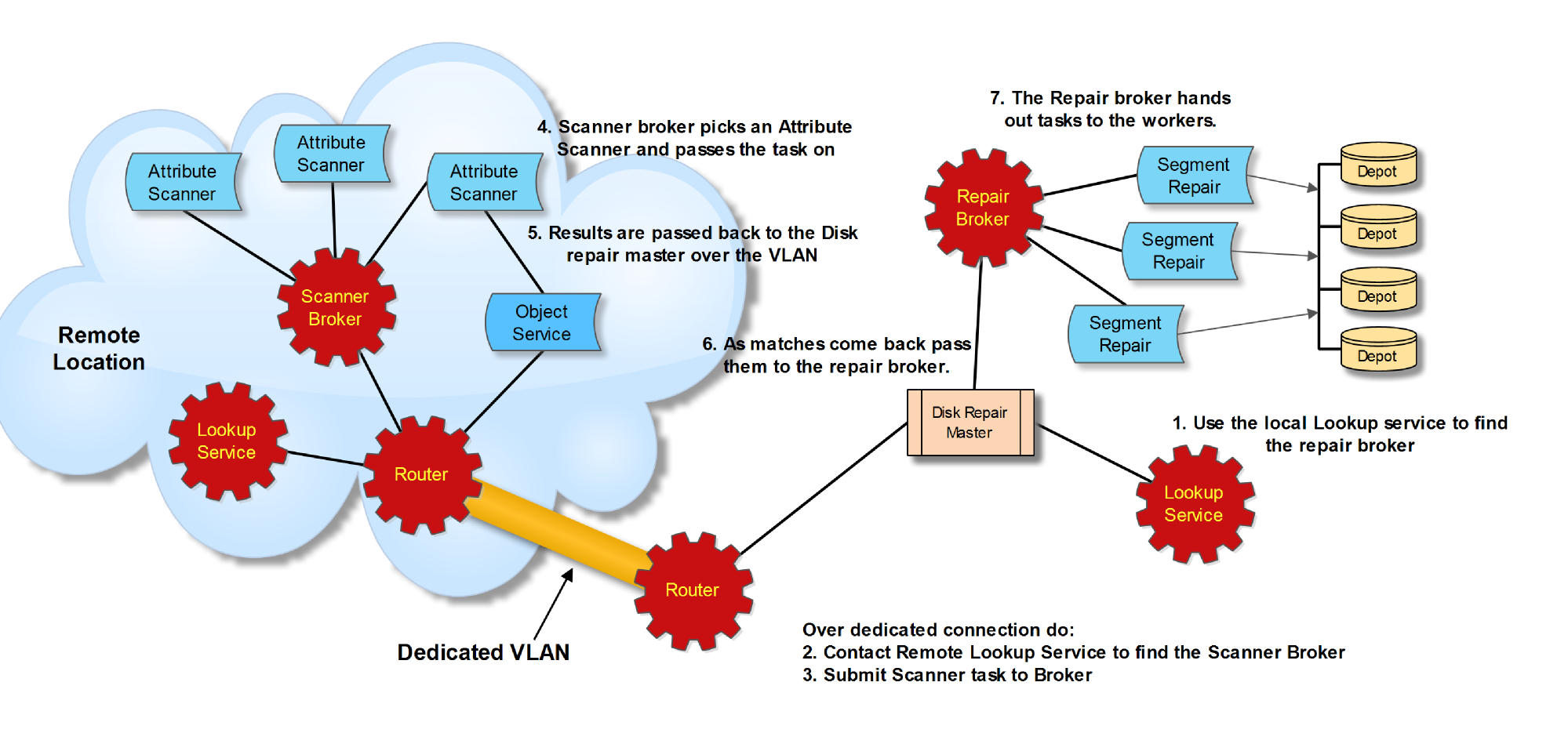
Example MQ data flow usage for repairing failed drives.
The figure above is designed to provide a feel for what can be accomplished with the MQ layer. In this example data is stored at multiple sites with the OS located in a single location. The remote site has a disk failure and it needs to be repaired. Conceptually this entails doing a scan of the file system looking for any eXnodes that use the failed drive and then run the repair process on the file, lio_inspect. The remote site is in the process of doing large scale data movement so a dedicated VLAN is set up to the primary site for high priority traffic. In this case, it would be metadata operations. Below is the sequence of events that would transpire.
- The Disk Repair Master (DRM) contacts the local MQ lookup service to see which nodes offer a broker repair service.
- Now the DRM does the same thing at the remote site looking for an Attribute Scanner broker. Since this is high priority traffic it jumps on the dedicated VLAN using the MQ router nodes. It could go directly to the remote lookup service, but would be competing with the data transfer traffic.
- After finding an Attribute Scanner broker the DRM submits the attribute scanning task to the broker. The broker finds a worker bee attribute scanner and assigns it the task.
- The Attribute Scanner then executes the task: Scan the entire file system looking at the system.exnode attribute. If the exNode has the resource in question, notify the DRM.
- Since this is high priority, the results are sent back over the dedicated VLAN.
- The DRM then sends the filename to the Repair Broker found in step 1.
- The Repair Broker then assigns the task to a Segment Repair worker in a round robin fashion. Additional Segment repair workers can be added to expedite the repair time.
There are many other things that can be done with the MQ layer. This is just designed as an example. One real world example, we plan on implementing, is a local caching service. The idea is to use local depots to cache frequently used data storing the augmented exNode in a local OS. This would be accomplished by encapsulating the existing exNode with a new log segment, segment_log driver, using the normal file exNode as the base. Using this approach frequently accessed data would be stored in the log on local depots. Anything not in the log would fall through to the base segment and be pulled from the remote site.
Deciding on what to cache locally would be done by instrumenting the segment read/write operations to publish any I/O operations via MQ with a Local Segment Caching service subscribed to the data stream mining it for hot spots. When a hot spot is detected it would trigger the creation of a log segment as described above and prefetch the active data. The new eXnode could then be used on subsequent opens and I/O operations.
In summary, the MQ layer provides a pluggable generic task execution framework, similar in concept to micro-services in iRODS. Micro-services in iRODS focuses on providing a client/server task execution framework which would be classified as a subset of L-Store’s MQ framework.
Glossary
- Allocation
- Space reserved for a file on an individual depot. This information is contained in the exNode. Access to the data is controlled by read, write, and manage capabilities. Each allocation has a unique set of capabilities.
- Attribute
- A keyword / value pair that is associated with a file. There are two distinct types: traditional and virtual.
- CMS
- Compact Muon Solenoid experiment for the Large Hadron Collider (LHC). Vanderbilt is a Tier2 data center for CMS. The massive data storage and access needs of CMS are what continue to drive the development of the L-Store software package. The previous version of L-Store has been in full production mode with CMS for the last 3 years.
- Data block
- It defines how much of a given allocation is used by a particular file. A file is defined by one or more allocations.
- Data Service (DS)
- This service is responsible for block level data movement and storage. Currently IBP is the only implementation supported.
- Depot
- A server with minimal data management software and a heterogeneous collection of hard drives.
- exNode
- Contains the metadata (file size, location of data on depots, etc.) associated with a given file. An exNode is the L-Store version of a Linux/Unix inode. It contains the data blocks and the information needed to reassemble the data blocks into a file.
- Logistical Input/Output (LIO)
- A command line software suite for reading and writing data in L-Store. It is an interface to L-Store that allows for fine control of the data flow.
- Logistical File System (LFS)
- A mountable file system that allows the user to access all of the L-Store data as if it were an external hard drive. This is the preferred method for users and applications to interact with the L-Store namespace.
- Logistical Networking (LN)
- A system architecture concept in which the use of storage to decouple data generation and consumption from end-to-end data transfer, generalizing the paths available through time and space.
- L-Store
- The unified software namespace that connects all the depots together into a cloud. The exNodes are part of L-Store.
- Metadata
- Data associated with a file that describes it in some way. This can include file size, location of the hardware resource, access time, checksum information, arbitrary tagging information etc.
- Object Service (OS)
- Provides the traditional file system semantics for manipulating files and directories. It also provides support for arbitrary metadata to be associated with any object.
- Reed-Solomon
- A way of encoding data that is the generalization or RAID5 and RAID6 to support arbitrary numbers of drive failures. Often denoted RS-D+P where D is the number of data disks and P is the number of parity disks.
- Resource Service (RS)
- is responsible for mapping resource requests to physical resources and monitoring the health of physical resources
- Segment
- A driver that controls data placement and layout, and optionally interactions with the rest of the services.
- Segment Service
- This service consists of software drivers that control the logical layout of data on physical resources. These drivers could be designed to interface to other repositories, for example iRODS, S3, or WebDAV for example providing whole file access. They can also perform block-level I/O using the Data Service to perform sophisticated fault tolerance and caching schemes.
- Traditional Attribute
- Is a key value pair associated with a file and stored on the filesystem.
- Virtual Attribute
- Attribute that is calculated on demand from other attributes. This is effectively a small script that gets activated by an attribute query.